Ein Vergleich von VPUs, GPUs und FPGAs für die Deep Learning Inferenz

Einführung
Beim Einstieg in Deep Learning für die industrielle Bildverarbeitung ist die Auswahl der Hardware, auf der die Inferenz ausgeführt werden soll, von entscheidender Bedeutung. Grafikprozessoren (GPUs), Field Programmable Gate Arrays (FPGAs) und Bildverarbeitungs-Prozessoren (VPUs) verfügen jeweils über Vorteile und Einschränkungen, die Ihr Systemkonzept beeinflussen können. Diser Artikel erläutert die Eigenschaften und wie Sie die richtige Plattform für Ihre Anwendungszwecke bestimmen.
GPU
GPUs sind aufgrund ihrer hochparalellisierten Verarbeitungsarchitektur optimal für die Beschleunigung von Deep Learning Inferenz geeignet. Nvidia hat intensiv in die Entwicklung von Tools für Deep Learning und Inferenz investiert, die auf Nvidia's CUDA-Kernen (Compute Unified Device Architecture) ausgeführt werden können. Die beliebte GPU-Unterstützung von Google TensorFlow ist für CUDA-fähige GPUs von Nvidia bestimmt. Einige GPUs sind mit Tausenden von Prozessorkernen ausgestattet und eignen sich optimal für rechnerisch anspruchsvolle Aufgaben wie die autonome Fahrzeugführung sowie für Trainingsnetzwerke, die dem Einsatz mit weniger leistungsfähiger Hardware dienen werden. In der Regel verbrauchen GPUs sehr viel Strom. Der RTX 2080 erfordert 225 W, während der Jetson TX2 bis zu 15 W verbraucht. GPUs sind außerdem teuer. Der RTX 2080 kostet 800 US-Dollar.
FPGA
FPGAs sind in der Branche der industriellen Bildverarbeitung weit verbreitet. Die meisten Kameras zur industriellen Bildverarbeitung und die meisten Framegrabber basieren auf FPGAs. FPGAs vereinen die Flexibilität und Programmierbarkeit von Software, die auf einem Allzweck-Prozessor (CPU) ausgeführt wird, mit der Geschwindigkeit und Energieeffizienz einer anwendungsspezifischen integrierten Schaltung (Application Specific Integrated Circuit bzw. ASIC). Eine Intel®™ Aria 10 FPGA-basierte PCIe Vision Accelerator-Karte verbraucht bis zu 60 W Energie und ist für 1500 US-Dollar erhältlich.
Ein Nachteil der Einsatzes von FPGAs besteht darin, dass die FPGA-Programmierung sehr spezielles Wissen und Erfahrung erfordert. Die Entwicklung neuronaler Netzwerke für FPGAs ist aufwändig und zeitintensiv. Zwar können Entwickler auf Tools von Drittanbietern zurückgreifen, um Aufgaben zu vereinfachen, doch diese Tools sind für gewöhnlich teuer und können Benutzer an geschlossene Ökosysteme proprietärer Technologien binden.
VPU
Bildverarbeitungseinheiten (Vision Processing Units) sind eine Art System-On-Chip (SOC), die der Erfassung und Auswertung visueller Informationen dienen. Sie wurden für die mobile Anwendung entwickelt und sind auf geringe Größe und Energieeffizienz optimiert. Die Intel® Movidius™ Myriad™ 2 VPU ist dafür das perfekte Beispiel: Sie kann mit einem CMOS-Bildsensor (CIS) verbunden werden, die erfassten Bilddaten vorverarbeiten, dann die erzeugten Bilder durch ein zuvor trainiertes neuronales Netz verarbeiten und schließlich ein Ergebnis ausgeben – all das bei weniger als 1 W Energieverbrauch. Die Myriad-VPUs von Intel kombinieren herkömmliche CPU-Kerne mit Vektorverarbeitungskernen, um so die hohe Verzweigungslogik zu beschleunigen, die bei neuronalen Netzen für Deep Learning typisch ist.
VPUs eignen sich ideal für Embedded-Anwendungen. Zwar sind sie weniger leistungsfähig als GPUs, doch aufgrund ihrer geringen Größe und der hohen Energieeffizienz lassen sie sich in äußerst kleine Gehäuse integrieren. Die demnächst verfügbare FLIR Firefly-Kamera mit integriertem Myriad 2 VPU ist zum Beispiel nicht einmal halb so groß wie eine Standard-„Ice Cube“-Kamera zur industriellen Bildverarbeitung. Dank ihrer Energieeffizienz eignen sich VPUs ideal für Handgeräte, mobile Anwendungen oder Drohnen, bei denen eine lange Akkulaufzeit von Vorteil ist.
Intel hat für seine Movidius Myriad-VPUs ein offenes Ökosystem entwickelt, mit dem Benutzer die Deep-Learning Frameworks und die Werkzeuge ihrer Wahl einsetzen können. Der Intel Neural Compute Stick verfügt über eine USB-Schnittstelle und kostet 80 US-Dollar.
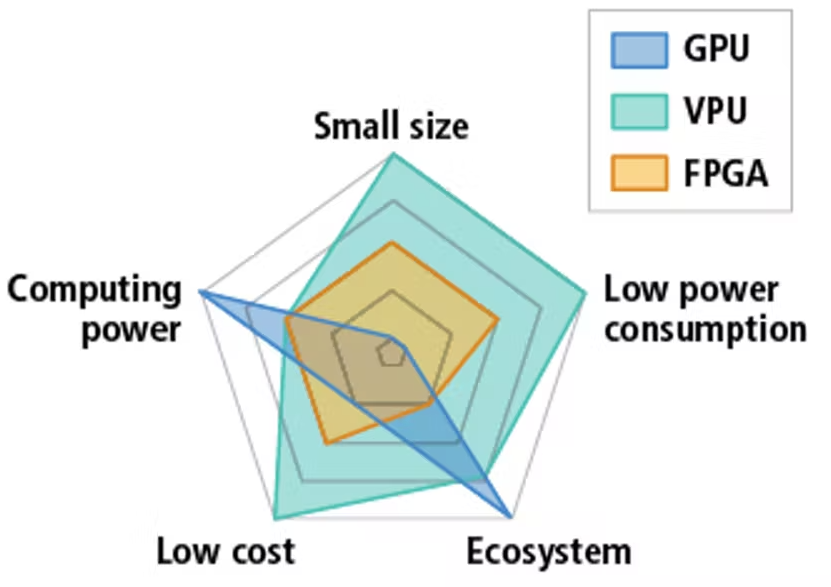
Abb. 1 Relative Leistung herkömmlicher Hardware zur Beschleunigung von Inferenz.
Geschätzte Leistungsfähigkeit unterschiedlicher Hardware
Durch die Unterschiede in der Verarbeitungsarchitektur zwischen GPUs, SOCs und VPUs sind reine Leistungsvergleiche unter Verwendung von FLOPS-Werten (Floating-Point-Operationen pro Sekunde) von geringerem Nutzen. Der Vergleich der veröffentlichten Inferenzzeiten kann als nützlicher Ausgangspunkt dienen, die reine Inferenzzeit allein kann allerdings irreführend sein. Während die Inferenzzeit für ein Einzelbild auf dem Intel Movidius Myriad 2 möglicherweise schneller ist als auf dem Nvidia Jetson TX2, kann der TX2 mehrere Bilder gleichzeitig verarbeiten, wodurch insgesamt eine höhere Verarbeitungsgeschwindigkeit erzielt wird. Der TX2 kann im Gegensatz zum Myriad 2 gleichzeitig weitere Datenverarbeitungsaufgaben ausführen. Ohne Tests fällt der Vergleich heutzutage schwer.
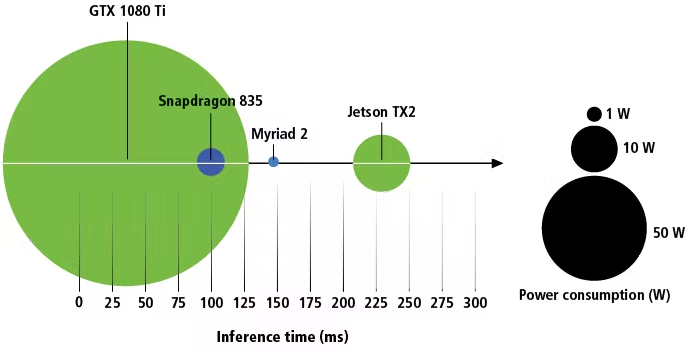
Abb. 2 Stromverbrauch vs. Einzelbild-Inferenzzeit
Fazit
Bevor die Entscheidung über die Hardware eines inferenzfähiges industrielles Bildverarbeitungssystem gefällt wird, sollte der Entwickler Tests durchführen, um die für seine Anwendung erforderliche Genauigkeit und Geschwindigkeit zu ermitteln. Diese Parameter entscheiden über die erforderlichen Eigenschaften des neuronalen Netzes und die Hardware, mit der es eingesetzt werden kann.
Zugehörige Artikel
-
 Anwendungsbericht
Anwendungsbericht
ÖLLAGERBETREIBER VERLÄSST SICH BEIM BRANDSCHUTZ SEINES 160 HEKTAR GROSSEN BETRIEBSGELÄNDES AUF FLIR
Bericht lesen -
 Sonstige
Sonstige
a50-a70 Formularseite zum Kontaktieren eines Experten
Bericht lesen -
 Fallstudie
Fallstudie
Die Radiometrischen Wärmebildkameras Von FLIR Schützen Ecologica Tredi Gegen Brände
Bericht lesen