So erstellen Sie ein individuelles eingebettetes Stereosystem für die Tiefenwahrnehmung

Für 3D-Sensoren gibt es verschiedene Optionen zur Entwicklung von Systemen für die Tiefenwahrnehmung, einschließlich Stereo-Sicht mit Kameras, Lidar und Laufzeitsensoren. Jede Option hat ihre Stärken und Schwächen. Ein Stereosystem ist in der Regel kostengünstig, robust genug für den Einsatz im Freien und kann eine hochauflösende Farbpunktwolke darstellen.
Auf dem Markt gibt es heute verschiedene Stereosysteme von der Stange. Abhängig von Faktoren wie Genauigkeit, Basislinie, Sichtfeld und Auflösung müssen die Systemingenieure manchmal ein kundenspezifisches System erstellen, um die Anforderungen spezifischer Anwendungen zu erfüllen.
Eine weitere Anwendung, die von einem solchen Onboard-Verarbeitungssystem stark profitieren kann, ist die Objekterkennung. Mit den Fortschritten im Bereich Deep Learning ist es relativ einfach geworden, Anwendungen um eine Objekterkennung zu erweitern. Aber der Bedarf an dedizierten GPU-Ressourcen macht es für viele Benutzer unerschwinglich. In diesem Artikel besprechen wir auch, wie Sie Ihre Stereo-Vision-Anwendung um Deep Learning erweitern können, ohne dass eine teure Host-GPU erforderlich ist. Wir haben den Beispielcode und die Abschnitte dieses Artikels in Stereo Vision und Deep Learning unterteilt. Wenn Ihre Anwendung also kein Deep Learning erfordert, können Sie die Deep Learning-Abschnitte überspringen.
Stereo Vision – Überblick
Stereo-Sicht ist die Extraktion von 3D-Informationen aus digitalen Bildern durch Vergleichen der Informationen in einer Szene aus zwei verschiedenen Blickwinkeln. Die relativen Positionen eines Objektes in zwei Bildebenen liefern Informationen über die Tiefe des Objektes aus dem .
Ein Überblick über ein Stereo-Sichtsystem ist in Abbildung 1 dargestellt. Es besteht aus den folgenden wesentlichen Schritten:
- Kalibrierung: Die Kalibrierung der Kamera schließt die intrinsische und die extrinsische Kalibrierung ein. Die intrinsische Kalibrierung bestimmt die Bildmitte, die Brennweite und die Verzerrungsparameter, während die extrinsische Kalibrierung die Positionen der Kameras in den drei Dimensionen bestimmt. Dies ist ein entscheidender Schritt bei vielen Anwendungen für die Computer-Sicht, insbesondere wenn metrische Informationen zu der Szene erforderlich sind, wie z. B. die Tiefe. Den Kalibrierungsschritt werden wir in Abschnitt 5 weiter unten im Detail besprechen.
- Entzerrung: Die Stereo-Entzerrung ist der Prozess der Reprojektion von Bildebenen auf eine gemeinsame Ebene parallel zur Linie zwischen den Mittelpunkten der Kameras. Nach der Korrektur liegen korrespondierende Punkte in derselben Zeile, was die Kosten und die Unklarheit des Abgleichs erheblich reduziert. Dieser Schritt wird mit dem bereitgestellten Code durchgeführt, mit dem Sie Ihr eigenes System erstellen können.
- Stereo-Abgleich: Dies ist der Prozess des Abgleichens von Pixeln zwischen dem linken und rechten Bild, der Disparitätsabbildungen erzeugt. Der SGM-Algorithmus (Semi-Global Matching) wird im bereitgestellten Code verwendet, mit dem Sie Ihr eigenes System erstellen können.
- Triangulation: Triangulation ist der Prozess zur Bestimmung eines Punktes im dreidimensionalen Raum anhand seiner Projektion auf die beiden Bilder. Die Disparitätsabbildung wird in eine 3D-Punktwolke konvertiert.
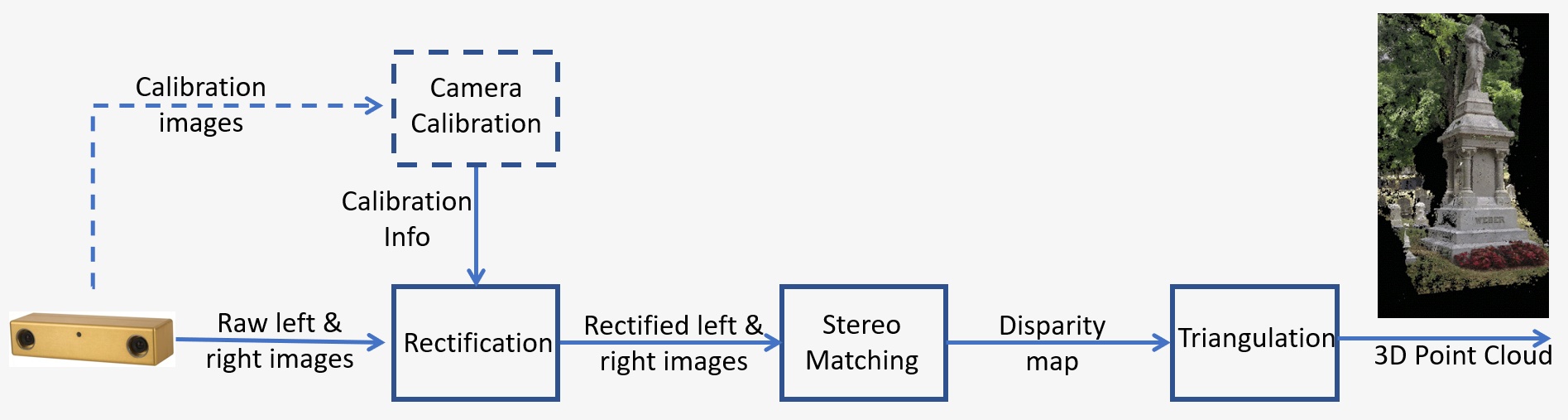
Abbildung 1: Übersicht über ein Stereo-Sichtsystem
Übersicht über Deep Learning
Deep Learning ist ein Teilgebiet des maschinellen Lernens, das sich mit Algorithmen beschäftigt, die von der Struktur und Funktion des Gehirns inspiriert sind. Es versucht, die Lernfähigkeit des menschlichen Gehirns nachzuahmen. Deep-Learning-Algorithmen können komplexe Operationen wie Objekterkennung, Klassifizierung, Segmentierung usw. effizient ausführen. Deep Learning ermöglicht es Maschinen unter anderem, Personen und Objekte in den ihr zugeführten Bildern zu erkennen. Die spezielle Anwendung, an der wir interessiert sind, ist die Personenerkennung. Das Trainieren Ihrer eigenen Deep-Learning-Algorithmen erfordert eine große Menge an gekennzeichneten Trainingsdaten, aber vortrainierte Open-Source-Modelle erleichtern es jedem, diese Anwendungen zu entwickeln.
Deep Learning erfordert zudem Hochleistungs-GPUs, aber die Quartet-Lösung für TX2 bietet alle Funktionen einer größeren GPU zu einem Bruchteil des Formfaktors und des Stromverbrauchs. Die Ausführung der Deep-Learning-Modelle auf dem TX2 bietet zudem den zusätzlichen Vorteil der Mobilität und ist ein perfekter Kandidat für mobile Roboter, die Personen erkennen müssen, um sie zu meiden.
Konstruktionsbeispiel
Wir wollen einmal ein Konstruktionsbeispiel für ein Stereosystem betrachten. Hier sind die Anforderungen an eine mobile Roboteranwendung in einer dynamischen Umgebung mit sich schnell bewegenden Objekten. Die zu erfassende Szene ist 2 m groß, der Abstand von den Kameras zur Szene beträgt 3 m und die gewünschte Genauigkeit beträgt 1 cm bei 3 m.
Weitere Informationen zur Stereogenauigkeit finden Sie in diesem Artikel. Der Tiefenfehler ist gegeben durch: ΔZ=Z²/Bf * Δd, abhängig von folgenden Faktoren:
- Z ist der Bereich
- B ist die Basislinie
- f ist die Brennweite in Pixeln, die mit dem Kamerasichtfeld und der Bildauflösung zusammenhängt
Es gibt verschiedene Gestaltungsmöglichkeiten, die diese Anforderungen erfüllen können. Anhand der obigen Anforderungen an die Szenengröße und den Abstand können wir die Brennweite des Objektivs für einen bestimmten Sensor bestimmen. Zusammen mit der Basislinie können wir anhand der obigen Formel den erwarteten Tiefenfehler bei 3 m berechnen, um zu überprüfen, ob er die Anforderung an die Genauigkeit erfüllt.
In Abbildung 2 sind zwei Optionen dargestellt: Kameras mit niedrigerer Auflösung und einer längeren Basislinie oder Kameras mit höherer Auflösung und einer kürzeren Basislinie. Die erste Option ist eine größere Kamera, die jedoch einen geringeren Rechenbedarf hat, die zweite Option ist eine kompaktere Kamera, jedoch mit höherem Rechenbedarf. Für diese Anwendung haben wir uns für die zweite Option entschieden, da eine kompakte Größe für den mobilen Roboter eher wünschenswert ist, und wir können die Quartet Embedded Solution für TX2 verwenden, die über eine leistungsstarke GPU verfügt, die die Daten verarbeiten kann.

Abbildung 2: Optionen zur Konstruktion eines Stereosystems für eine Beispielanwendung
Hardware-Anforderungen
Bei diesem Beispiel montieren wir zwei Blackfly S-Platinenkameras mit 1,6 MP mit dem globalen Verschlusssensor IMX273 Sony Pregius auf einer 3D-gedruckten Leiste bei einer Basislinie von 12 cm. Beide Kameras verfügen über ähnliche 6-mm-Objektive mit S-Mount. Die Kameras werden über zwei FPC-Kabel mit der kundenspezifischen Trägerplatine Quartet Embedded Solution für TX2 verbunden. Um die linke mit der rechten Kamera zu synchronisieren und die Bilder gleichzeitig aufzunehmen, wird ein Synchronisationskabel zwischen den beiden Kameras angebracht. Abbildung 3 zeigt die Vorder- und Rückansicht unseres kundenspezifischen eingebetteten Stereosystems.

Abbildung 3: Vorder- und Rückansicht unseres kundenspezifischen eingebetteten Stereosystems
In der folgenden Tabelle sind alle Hardwarekomponenten aufgeführt:
|
Teil |
Beschreibung |
Anzahl |
Link |
|
ACC-01-6005 |
Quartettträger mit TX2 Modul 8 GB |
1 |
https://www.flir.com/products/quartet-embedded-solution-for-tx2/ |
|
BFS-U3-16S2C-BD2 |
1,6 MP, 226 FPS, Sony IMX273, Color |
2 |
|
|
ACC-01-5009 |
S-Mount & IR-Filter für BFS Platinenfarbkameras |
2 |
|
|
BW3M60B-1000 |
6 mm S-Mount-Objektiv |
|
http://www.boowon.co.kr/site/ |
|
ACC-01-2401 |
FPC-Kabel (15 cm) für Blackfly S Platinenkameras |
2 |
https://www.flir.com/products/15-cm-fpc-cable-for-board-level-blackfly-s/ |
|
XHG302 |
NVIDIA® Jetson™ TX2/TX2 4GB/TX2i Aktiver Kühlkörper |
1 |
https://connecttech.com/product/nvidia-jetson-tx2-tx1-active-heat-sink/ |
|
Synchronisationskabel (zum Selbermachen) |
1 |
||
|
Montagestange (zum Selbermachen) |
1 |
Beide Objektive sollten so eingestellt werden, dass die Kameras auf die Entfernungen ausgerichtet sind, die für Ihre Anwendung erforderlich sind. Ziehen Sie die Schraube (in Abbildung 4 rot eingekreist) an jedem Objektiv fest, um den Fokus zu halten.

Abbildung 4: Seitenansicht unseres Stereosystems mit der Objektivschraube
Benötigte Software
a. Spinnaker
Teledyne FLIR Spinnaker SDK ist auf Ihren eingebetteten Quartett-Lösungen für TX2 vorinstalliert. Spinnaker muss mit den Kameras kommunizieren.
b. OpenCV 4.5.2 mit CUDA-Unterstützung
OpenCV Version 4.5.1 oder neuer ist für SGM erforderlich, den Stereo-Abgleichs-Algorithmus, den wir verwenden. Laden Sie die Zip-Datei mit dem Code für diesen Artikel herunter und entpacken Sie sie in den Ordner „StereoDepth“. Das Skript zur Installation von OpenCV ist OpenCVInstaller.sh. Geben Sie die folgenden Befehle in einem Terminalfenster ein:
- cd ~/StereoDepth
- chmod +x OpenCVInstaller.sh
- ./OpenCVInstaller.sh
Das Installationsprogramm wird Sie auffordern, Ihr Administratorkennwort einzugeben. Das Installationsprogramm beginnt mit der Installation von OpenCV 4.5.2. Es kann einige Stunden dauern, OpenCV herunterzuladen und zu erstellen.
Jetson-inference (wenn Deep Learning benötigt wird)
Jetson-inference ist eine Open-Source-Bibliothek von NVIDIA, die für GPU-beschleunigtes Deep Learning auf Jetson-Geräten wie dem TX2 verwendet werden kann. Die Bibliothek nutzt das TensorRT SDK, das eine leistungsstarke Inferenz auf NVIDIA-GPUs ermöglicht. Jetson-inference bietet dem Benutzer eine Reihe von vortrainierten und einsatzbereiten Deep-Learning-Modellen und den Code, um diese Modelle mit TensorRT bereitzustellen. Um Jetson-inference zu installieren, geben Sie folgende Befehle in ein Terminal ein:
- cd ~/StereoDepth
- chmod +x InferenceInstaller.sh
- ./InferenceInstaller.sh
Kalibrierung
Der Code zum Erfassen und Kalibrieren von Stereobildern befindet sich im Ordner „Kalibrierung“. Die Seriennummern für die linke und rechte Kamera können Sie mit dem SpinView GUI identifizieren. Für unsere Einstellungen ist die rechte Kamera der Master und die linke Kamera der Slave. Kopieren Sie die Seriennummern der Master- und der Slave-Kamera in Zeilen 60 und 61 der Datei grabStereoImages.cpp. Erstellen Sie die ausführbare Datei mithilfe der folgenden Befehle in einem Terminal:
- cd ~/StereoDepth/Calibration
- mkdir build
- mkdir -p images/{left, right}
- cd build
- cmake ..
- make
Drucken Sie das Schachbrettmuster aus, das Sie unter diesem Link finden, und befestigen Sie es auf einer flachen Oberfläche, um es als Kalibrierungsziel zu verwenden. Optimale Ergebnisse während der Kalibrierung erhalten Sie, wenn Sie in SpinView die automatische Belichtung auf Aus schalten und die Belichtung so anpassen, dass das Schachbrettmuster klar sichtbar ist und die weißen Quadrate nicht zu stark belichtet werden, wie in Abbildung 5 dargestellt. Nach der Erfassung der Kalibrierungsbilder können in SpinView die Verstärkung und die Belichtung auf Automatik gestellt werden.
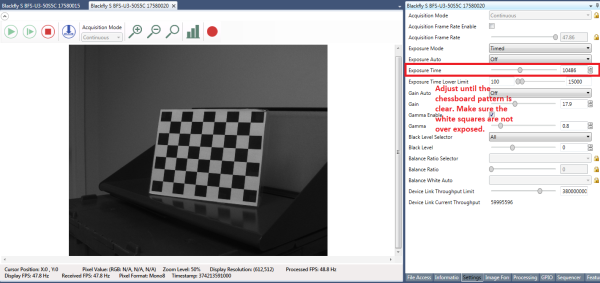
Abbildung 5: Einstellungen für SpinView GUI
Um mit der Erfassung von Bildern zu beginnen, geben Sie ein
- ./grabStereoImages
Der Code sollte beginnen, Bilder mit etwa 1 Frame/Sekunde zu erfassen. Die linken Bilder werden im Ordner Bilder/links und die rechten Bilder im Ordner Bilder/rechts gespeichert. Bewegen Sie das Ziel so, dass es in jeder Ecke des Bildes erscheint. Sie können das Ziel drehen und Bilder davon aus der Nähe und aus einiger Entfernung aufnehmen. Standardmäßig erfasst das Programm 100 Bildpaare, kann jedoch mit Hilfe eines Befehlszeilenarguments geändert werden:
- ./grabStereoImages 20
So werden nur 20 Bildpaare erfasst. Beachten Sie bitte, dass dadurch alle Bilder überschrieben werden, die in den Ordnern gespeichert sind. Einige Beispielbilder zur Kalibrierung sind in Abbildung 6 gezeigt.

Abbildung 6: Beispielbilder zur Kalibrierung
Führen Sie nach der Aufnahme der Bilder den Python-Kalibrierungscode aus, indem Sie Folgendes eingeben:
- cd ~/StereoDepth/Calibration
- python cameraCalibration.py
Damit werden 2 Dateien namens „intrinsics.yml“ und „extrinsics.yml“ erstellt, die die intrinsischen und extrinsischen Parameter des Stereosystems enthalten. Der Code nimmt standardmäßig eine Größe der Schachbrettquadrate von 30 mm an. Dies kann jedoch ggf. geändert werden. Am Ende der Kalibrierung wird der RMS-Fehler angezeigt, der angibt, wie gut die Kalibrierung ist. Der RMS-Fehler sollte für eine gute Kalibrierung typischerweise unter 0,5 Pixel liegen.
Echtzeit-Tiefenkarte
Der Code zur Berechnung der Ungleichheit in Echtzeit befindet sich im Ordner „Depth“. Kopieren Sie die Seriennummern der Kameras in die Zeilen 230 und 231 der Datei live_disparity.cpp. Erstellen Sie die ausführbare Datei mithilfe der folgenden Befehle in einem Terminal:
- cd ~/StereoDepth/Depth
- mkdir build
- cd build
- cmake ..
- make
Kopieren Sie die im Kalibrierungsschritt erhaltenen Dateien „intrinsics.yml“ und „extrinsics.yml“ in diesen Ordner. Zum Ausführen der Echtzeit-Demo der Tiefenkarte geben Sie ein
- ./live_disparity
Dann müssten das linke Kamerabild (rohes, nicht korrigiertes Bild) und die Tiefenkarte (unsere endgültige Ausgabe) angezeigt werden. Einige exemplarische Ausgaben sind in Abbildung 7 dargestellt. Der Abstand zur Kamera ist entsprechend der Legende rechts auf der Tiefenkarte farbcodiert. Der schwarze Bereich auf der Tiefenkarte bedeutet, dass in diesem Bereich keine Disparitätsdaten gefunden wurden. Dank dem Grafikprozessor NVIDIA Jetson TX2 können bis zu 5 Frames/Sekunde mit einer Auflösung von 1440 × 1080 und bis zu 13 Frames/Sekunde mit einer Auflösung von 720 × 540 ausgeführt werden.
Um die Tiefe an einem bestimmten Punkt zu sehen, klicken Sie auf diesen Punkt auf der Tiefenkarte. Dann wird die Tiefe angezeigt, wie im letzten Beispiel in Abbildung 7 gezeigt.

Abbildung 7: Beispielbilder von der linken Kamera und entsprechende Tiefenkarte. Die untere Tiefenkarte zeigt außerdem die Tiefe an einem bestimmten Punkt.
Personenerkennung
Wir verwenden DetectNet von Jetson-inference, um Menschen in einem Bildframe zu erkennen. DetectNet bietet Optionen zur Auswahl der Deep-Learning-Modellarchitektur für die Objekterkennung. Wir verwenden die Single Shot Detection (SSD)-Architektur mit einem MobileNetV2-Backbone, um sowohl Geschwindigkeit als auch Genauigkeit zu optimieren. Wenn die Demo zum ersten Mal ausgeführt wird, erstellt TensorRT eine serialisierte Engine, um die Inferenzgeschwindigkeit weiter zu optimieren. Das kann einige Minuten dauern. Diese Engine wird automatisch für weitere Läufe in Dateien gespeichert. Die verwendete Architektur ist sehr effizient und man kann ~50 fps für den Betrieb des Erkennungsmoduls erwarten. Der Code für die Personenerkennung zusammen mit der Stereotiefe in Echtzeit befindet sich im Ordner „DepthAndDetection”. Kopieren Sie die Seriennummern der Kameras, um live_disparity.cpp Zeilen 271 und 272 zu archivieren. Erstellen Sie die ausführbare Datei mit den folgenden Befehlen in einem Terminal:
cd ~/StereoDepth/DepthAndDetectionmkdir buildcd buildcmake ..make
Kopieren Sie die Dateien „intrinsics.yml” und „extrinsics.yml”, die Sie im Kalibrierungsschritt erhalten haben, in diesen Ordner. Um die Echtzeit-Tiefenkartendemo auszuführen, geben Sie Folgendes ein:
./live_disparity
Zwei Fenster mit den links korrigierten Farbbildern und der Tiefenkarte werden angezeigt. Die Tiefenkarte ist zur besseren Visualisierung der Tiefenkarte farbcodiert. Beide Fenster haben Begrenzungskästen, die die Personen im Frame umgeben und die durchschnittliche Entfernung der Person von der Kamera anzeigen. Sowohl mit Stereoverarbeitung als auch mit Deep-Learning-Inferenz läuft die Demo mit etwa ~4 fps bei einer Auflösung von 1440 × 1080 und bis zu 11,5 fps für eine Auflösung von 720 × 540.

Abbildung 1: Beispielbilder der linken Kamera und entsprechende Tiefenkarte. Alle Bilder zeigen die auf den Bildern erkannte Person und die Entfernung der Person von der Kamera
Der Personenerkennungsalgorithmus ist in der Lage, mehrere Personen auch unter schwierigen Bedingungen wie Okklusion zu erkennen. Der Code berechnet die Entfernungen zu allen im Bild erkannten Personen, wie unten gezeigt.

Abbildung 2: Das linke Bild und die Tiefenkarte zeigen mehrere Personen, die im Bild erkannt werden, und ihre entsprechende Entfernung von der Kamera.
Zusammenfassung
Die Verwendung der Stereo-Sicht für die Tiefenwahrnehmung hat die Vorteile, dass dies gut im Freien funktioniert und eine hochauflösende Tiefenkarte erstellt werden kann, und dies mit kostengünstigen Komponenten von der Stange. Je nach den Anforderungen gibt es eine Reihe von handelsüblichen Stereosystemen auf dem Markt. Sollten Sie ein kundenspezifisches eingebettetes Stereosystem entwickeln müssen, ist dies mit den hier gegebenen Anweisungen relativ einfach möglich.
Zugehörige Artikel
-
Embedded-Vision
So erstellen Sie ein individuelles eingebettetes Stereosystem für die Tiefenwahrnehmung
Weitere Informationen -
 Embedded-Vision
Embedded-Vision
Streaming 4 Kameras mit kleiner Trägerplatine: Schneller Prototyp
Bericht lesen -
 Embedded-Vision
Embedded-Vision
Leitfaden zur Integration von Platinenkameras
Bericht lesen